import nltk
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords
import numpy as np
import random
import json
from collections import Counter
import tensorflow as tf
import numpy as np
import time
import sqlite3
# Setup output logging to give us better visibility into progress
import logging
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__)
# Instatiate a lemmatizer to use in creating the word stem set
lemmatizer = WordNetLemmatizer()SENTIMENT ANALYSIS OF THE BIBLE(?) USING NLTK AND TENSORFLOW
using a model trained on rotten tomatoes movie reviews

Moses pixelated by Dall-E 3
Background
The Bible is one of the best selling books of all time, rich with many stories and characters (some controversial), and is a core pillar of the largest religion in the world (again not without controversy). I thought it would be a fun exercise to gauge the temperature of the language used in all the books of the Old and New testament. This is a simple proof of concept utilizing NLP (Natural Language Processing) techniques and Tensorflow to perform a sentiment analysis on the bible. We will use a pre-labeled dataset of a movie review corpus to train our neural network, and then run the Bible text through it to get the sentiment per book/chapter/verse in the form of 0 for negative and 1 for positive. I have decided to go with a modern translation called The Message, the language of which will hopefully align better with the movie review training set. Disclaimer: This is a proof of concept of the ML workflow, not meant to be a definitive analysis of the Bible itself.
High Level Approach
- Create an array of the most frequently occuring words from the negative and positive training data sets, aka bag of words model and lemmatize them, i.e. convert them into their simplest form.
- Create feature/label set for positive and negative sentiment data by counting the number of popular words in each sample, from the array created above
- Using the above labelled features as inputs, train a 3 layer feedfoward neural network which will output an array containing probability percentages for True and False
- We will save the model and then run it on the Bible (MSG) outputting the results to a sqlite database
- Visualize results
Importing modules and basic setup
Pre-process our labeled movie review data set
Let’s define a method, create_lexicon(), which will comb through all of our positive and negative training data to extract the most frequently used words which appear at least 50 times. These will be converted into their simplified forms and then duplicates will be removed.
For example it would convert this:
Hello this is a test. Hello world. The sky is grey today and my clown hair is red.
The cats wearing red hats sit back on the mat and put down like a clown who doesn't frown.
The sky is maybe not so grey but actually more red, like blood, like cat blood.
Tomorrow I will drink lots of black coffee mixed with gallons of paint.into this: (note how some words have been converted from plural to singular)
['hello', 'this', 'is', 'a', 'test', 'hello', 'world', 'the', 'sky', 'is', 'grey', 'today', 'and', 'my', 'clown', 'hair', 'is', 'red', 'the', 'cat', 'wearing', 'red', 'hat', 'sit', 'back', 'on', 'the', 'mat', 'and', 'put', 'down', 'like', 'a', 'clown', 'who', 'doe', 'frown', 'the', 'sky', 'is', 'maybe', 'not', 'so', 'grey', 'but', 'actually', 'more', 'red', 'like', 'blood', 'like', 'cat', 'blood', 'tomorrow', 'i', 'will', 'drink', 'lot', 'of', 'black', 'coffee', 'mixed', 'with', 'gallon', 'of', 'paint']and then count the words that only appear at least N times, if N=2:
['clown', 'a', 'sky', 'and', 'hello', 'of', 'is', 'blood', 'the', 'like', 'grey', 'red', 'cat']which will become our reference lexicon array for creating feature maps during training and actual usage. We can also consider removing stop words like “is”,“the”,“are” but in our case I found that our model accuracy actually decreased. This makes some sense in that we’re trying to analyze the Bible, words like He and Him are probably more important than they are in regular texts.
def create_lexicon(pos, neg, filename=None):
"""Create unique list of most frequently used words
(occuring more than 50 times) from negative
and postive corpus
"""
lexicon = []
for file in [pos, neg]:
with open(file, 'r') as f:
contents = f.readlines()
for l in contents:
all_words = word_tokenize(l.lower()) # split words into list
lexicon += list(all_words)
# lemmatize (simplify) all these words into their core form
lexicon = [lemmatizer.lemmatize(i) for i in lexicon]
lexicon = [ word for word in lexicon if word.isalpha() ]
# Could also append "and word not in stopwords.words('english')" to the above
# if we want to drop stop words
w_counts = Counter(lexicon)
final = [ word for word in w_counts if 1000 > w_counts[word] > 50 ]
if filename:
logger.debug('writing lexicon to {0}'.format(filename))
with open(filename, 'w') as lexifile:
json.dump(final, lexifile)
logger.debug('lexicon contains {0} words'.format(len(final)))
logger.debug('First 25 words:')
logger.debug(lexicon[:25])
return finalRepresenting phrases as numbers
We’ll need a way to convert our input phrases and sentences into feature arrays, encode_features(). In other words, how often do our lexicon words appear in a given input phrase?
Taking our previous example:
lexicon
['clown', 'a', 'sky', 'and', 'hello', 'of', 'is', 'blood', 'the', 'like', 'grey', 'red', 'cat']input phrase
"The blood of a calf is red like the dark sky."gets encoded as:
output feature array
[0, 0, 1, 0, 0, 0, 1, 1, 2, 1, 0, 1, 0]def encode_features(phrase, lexicon):
"""Given an input phrase, return an array of
the number of occurences of words from the
lexicon list created prior
"""
current_words = word_tokenize(phrase.lower())
current_words = [lemmatizer.lemmatize(i) for i in current_words]
features = np.zeros(len(lexicon))
for word in current_words:
if word.lower() in lexicon:
index_value = lexicon.index(word.lower())
features[index_value] += 1
features = list(features)
return featuresSplit the data into training and test groups
Now we need to split our movie reviews training data into training and testing groups (90%:10%) so Tensorflow can validate its results. We’ll also encode it with the above method and label it “(1,0)” for positive and “(0,1”) for negative.
def create_feature_sets_and_labels(pos, neg, test_size=0.1):
"""Take positive and negative sentiment files and
generate a list of features and labels from the
positive and negative sentiment data using the methods
above
"""
# Create frequently occuring word list
lexicon = create_lexicon(pos, neg, 'lexicon.json')
featureset = []
for sentiment_file, sentiment in ((pos, (1,0)),(neg, (0,1))):
with open(sentiment_file, 'r') as f:
contents = f.readlines()
for line in contents:
featureset.append((encode_features(line, lexicon), sentiment))
featureset = list(featureset)
random.shuffle(featureset)
logger.debug('features length is {}'.format(len(featureset)))
#logger.debug('First 5 features & labels:\n{0}'.format(featureset[:5]))
featureset = np.array(featureset)
testing_size = int(test_size * len(featureset))
# x is features, y is labels
train_x = list(featureset[:, 0][:-testing_size])
train_y = list(featureset[:, 1][:-testing_size])
test_x = list(featureset[:, 0][:-testing_size:])
test_y = list(featureset[:, 1][:-testing_size:])
return train_x, train_y, test_x, test_y, lexicon
# Create the train/test groups
train_x, train_y, test_x, test_y, lexicon = create_feature_sets_and_labels('pos.txt', 'neg.txt')DEBUG:__main__:writing lexicon to lexicon.json
DEBUG:__main__:lexicon contains 406 words
DEBUG:__main__:First 25 words:
DEBUG:__main__:['the', 'rock', 'is', 'destined', 'to', 'be', 'the', 'century', 'new', 'conan', 'and', 'that', 'he', 'going', 'to', 'make', 'a', 'splash', 'even', 'greater', 'than', 'arnold', 'schwarzenegger', 'van', 'damme']
DEBUG:__main__:features length is 10662Setup and train a deep neural network using our movie review dataset
We’re going to create a fully connected neural network (specifically a multilayer perceptron) consisting of 3 hidden layers and train it to output two classes, positive & negative sentiment, expressed as a probability of each (between 0 and 1).
# Conduct the actual training
tf.reset_default_graph()
# Define number of nodes (500) across 3 hidden layers
n_nodes_hl1 = 500
n_nodes_hl2 = 500
n_nodes_hl3 = 500
n_classes = 2
batch_size = 100 # can do batches of 100 features at a time
# Create a placeholder to accept our training set created
# above and referenced below
x = tf.placeholder('float', [None, len(train_x[0])], name='x') # [None by lengath of lexicon]
# Create a labels placeholder again created above and
# referenced below
y = tf.placeholder('float')
def linear(X, n_input, n_output, activation=None, scope=None):
"""Function to setup a basic neural network taking inputs
and producing outputs according to W * x + b all wrapped
by an activation function if defined"""
with tf.variable_scope(scope or "linear"):
W = tf.get_variable(
name='W',
shape=[n_input, n_output],
initializer=tf.random_normal_initializer(mean=0.0, stddev=0.1))
b = tf.get_variable(
name='b',
shape=[n_output],
initializer=tf.constant_initializer())
h = tf.matmul(X, W) + b
if activation is not None:
h = activation(h)
return h
def neural_network(data):
# layer 1 takes a phrase of text as input and outputs a matrix of size 500
h1 = linear(data, len(train_x[0]), n_nodes_hl1, tf.nn.relu, scope='layer1')
# layer 2 takes the output from above and spits out another matrix of size [500]
h2 = linear(h1, n_nodes_hl1, n_nodes_hl2, tf.nn.relu, scope='layer2')
# layer 3 (does the same as layer 2)
h3 = linear(h2, n_nodes_hl2, n_nodes_hl3, tf.nn.relu, scope='layer3')
# output layer takes the output from layer 3 and reduces it down to a matrix
# containing 2 values [percentage positive, percentage negative]
output = linear(h3, n_nodes_hl3, n_classes, None, scope='output')
return output
def train_neural_network(x):
prediction = neural_network(x)
# Calculate the loss (cross-entropy) between the predicted labels and the true labels
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=y))
# AdamOptimizer seems to automatically adjust the learning rate as opposed to
# GradientDescent's fixed
optimizer = tf.train.AdamOptimizer().minimize(cost)
#optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)
# Create a saver object to save our graph
saver = tf.train.Saver()
n_epochs = 10
tf.summary.scalar("cost", cost)
summary_op = tf.summary.merge_all()
# Save summary results to be able to view later using TensorBoard.
with tf.Session() as sess:
writer = tf.summary.FileWriter('summary/log', graph=sess.graph)
sess.run(tf.global_variables_initializer()) # initializes our variables. Session has now begun.
for epoch in range(n_epochs):
epoch_loss = 0 # we'll calculate the loss as we go
i = 0
while i < len(train_x):
#we want to take batches(chunks); take a slice, then another size)
start = i
end = i+batch_size
batch_x = np.array(train_x[start:end])
batch_y = np.array(train_y[start:end])
_, c, summary = sess.run([optimizer, cost, summary_op], feed_dict={x: batch_x, y: batch_y})
# write log to view stats in tensorboard
writer.add_summary(summary, epoch * n_epochs + i)
# Create a checkpoint in every iteration
#saver.save(sess, 'model/model_iter', global_step=epoch)
epoch_loss += c
i+=batch_size
print('Epoch', epoch, 'completed out of', n_epochs, 'loss:', epoch_loss)
pred_op = tf.nn.softmax(prediction, name='pred_op')
# Save the final model to file
saver.save(sess, 'model/model_final')
# Calculate the accuracy of predicted labels vs actual
correct = tf.equal(tf.argmax(prediction, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct, 'float'))
tf.summary.scalar("accuracy", accuracy)
print('Accuracy:', accuracy.eval({x: test_x, y: test_y}))
# Run classification against sample test data
feed_dict = {x: np.array([test_x[35]]).astype('float32')}
sentiment = sess.run(tf.nn.softmax(prediction), feed_dict)
print('sentiment is {}'.format(sentiment))
train_neural_network(x)Epoch 0 completed out of 10 loss: 64.5960595012
Epoch 1 completed out of 10 loss: 45.2602910995
Epoch 2 completed out of 10 loss: 30.1446892172
Epoch 3 completed out of 10 loss: 19.8478845358
Epoch 4 completed out of 10 loss: 23.3400688022
Epoch 5 completed out of 10 loss: 19.7552281469
Epoch 6 completed out of 10 loss: 13.5674309283
Epoch 7 completed out of 10 loss: 10.8786701597
Epoch 8 completed out of 10 loss: 8.56252970174
Epoch 9 completed out of 10 loss: 8.28067351319
Accuracy: 0.963422
sentiment is [[ 0.00291243 0.99708754]]Review results of training
Looking at the above, our training achieved 96.3% accuracy. Good enough for me! Let’s move forward.
Run the Bible against our model 🤞
# Load and use model
def run_prediction(book):
# Parse in MSG bible in JSON format
with open('MSG.json','r') as foo:
msg = foo.read()
msg = json.loads(msg)
# Read in the lexicon json defined above
with open('lexicon.json','r') as foo:
lexicon = foo.read()
lexicon = json.loads(lexicon)
# Zero out the model
tf.reset_default_graph()
with tf.Session() as sess:
# Create a saver object importing the previously trained model above
# Load the graph structure
saver = tf.train.import_meta_graph('model/model_final.meta')
# Restore the weights
saver.restore(sess, tf.train.latest_checkpoint('model/'))
# Get default graph (supply your custom graph if you have one)
graph = tf.get_default_graph()
# Retrieves the input placeholder tensor by name, which is where the encoded verses will be fed in for prediction.
x = graph.get_tensor_by_name("x:0")
# Retrieves the output operation (pred_op), which represents the predicted probabilities for positive and negative sentiment.
pred_op = graph.get_tensor_by_name("pred_op:0")
verses = []
# Create and connect to SQLite to save results
'''
sqlite> .schema bible
CREATE TABLE bible (book text, chapter int, verse int, sentiment int, pos real, neg real);
'''
conn = sqlite3.connect('bible.db')
c = conn.cursor()
print('# (Book, Chapter, Verse, Sentiment (0 for neg, 1 for pos), % pos, % neg)')
num = 0
epoch = int(time.time())
for chap in msg[book]:
for verse in msg[book][chap].items():
verse_info = {'chapter': chap,
'verse': verse[0],
'content': verse[1]}
try:
# Convert each verse into a numerical feature set which can be parsed in by the neural net
verse_info['content'] = np.array([encode_features(verse_info['content'], lexicon)]).astype('float32')
feed_dict = {x: verse_info['content']}
# Compute the sentiment of the verse
sentiment = sess.run(tf.nn.softmax(pred_op), feed_dict)
negpos = {0:'negative', 1:'positive'}
# Store results in a local set
summary = (book,
int(verse_info['chapter']),
int(verse_info['verse']),
int(sess.run(tf.argmin(sentiment,1))),
sentiment.tolist()[0][0],
sentiment.tolist()[0][1]
)
# Occasionally output progress (every 10th verse)
if num % 10 == 0:
cur_epoch = int(time.time())
delta_epoch = cur_epoch - epoch
epoch = cur_epoch
print(summary,delta_epoch)
num += 1
# Store the results to DB
c.execute('INSERT INTO bible VALUES (?,?,?,?,?,?)', summary)
except:
print(verse_info['content'])
conn.commit()
conn.close()
bible = ( '1 Kings', 'Colossians', '2 Corinthians', '2 Chronicles', 'Habakkuk', '1 Samuel',
'Acts', 'Psalms', 'Hosea', 'Daniel', 'James','Zechariah', 'Jonah', '1 Chronicles',
'Nehemiah', 'Romans', 'Micah', 'Isaiah', 'Jude', '2 Kings', '1 Corinthians', '2 John',
'3 John', 'Leviticus', '1 Peter', 'John', 'Nahum', 'Luke', 'Obadiah', 'Ephesians',
'1 Thessalonians', 'Galatians', 'Ezekiel', '2 Peter', 'Song of Solomon',
'1 Timothy','Haggai', 'Esther', '2 Timothy', 'Exodus', 'Joel', 'Philippians', 'Judges', 'Titus',
'Amos', '1 John', 'Mark', 'Genesis', 'Jeremiah', 'Numbers', 'Revelation', 'Ezra')
for book in bible:
run_prediction(book)INFO:tensorflow:Restoring parameters from model/model_finalINFO:tensorflow:Restoring parameters from model/model_final# (Book, Chapter, Verse, Sentiment (0 for neg, 1 for pos), % pos, % neg)
('1 Kings', 22, 48, 1, 0.7301628589630127, 0.2698371708393097) 0
('1 Kings', 22, 16, 0, 0.2689419388771057, 0.7310581207275391) 1
('1 Kings', 22, 36, 1, 0.5065181851387024, 0.49348175525665283) 0
('1 Kings', 22, 6, 1, 0.5343984961509705, 0.46560147404670715) 0
('1 Kings', 22, 43, 0, 0.2689417004585266, 0.7310582995414734) 1
('1 Kings', 22, 13, 0, 0.26902079582214355, 0.7309791445732117) 0
('1 Kings', 21, 2, 1, 0.7003198862075806, 0.29968008399009705) 0
('1 Kings', 21, 7, 0, 0.2689483165740967, 0.7310516834259033) 1
('1 Kings', 21, 23, 0, 0.28493088483810425, 0.7150691151618958) 0
('1 Kings', 6, 14, 0, 0.4769875705242157, 0.5230124592781067) 0
('1 Kings', 6, 32, 1, 0.7295066118240356, 0.27049335837364197) 1
('1 Kings', 6, 18, 1, 0.7309094071388245, 0.26909053325653076) 0
('1 Kings', 11, 6, 1, 0.5146255493164062, 0.4853745102882385) 1
('1 Kings', 11, 1, 0, 0.26983946561813354, 0.7301604747772217) 0
('1 Kings', 11, 7, 1, 0.7279067039489746, 0.2720933258533478) 1
('1 Kings', 11, 37, 0, 0.28705736994743347, 0.7129426002502441) 0
('1 Kings', 10, 21, 1, 0.7310167551040649, 0.26898324489593506) 1
('1 Kings', 10, 1, 0, 0.35356345772743225, 0.6464365720748901) 0
('1 Kings', 10, 15, 1, 0.7053192853927612, 0.29468071460723877) 0
('1 Kings', 2, 22, 1, 0.6499190926551819, 0.3500808775424957) 1
('1 Kings', 2, 8, 0, 0.26897111535072327, 0.7310289144515991) 1
('1 Kings', 2, 44, 0, 0.2765670716762543, 0.7234328985214233) 0
('1 Kings', 2, 4, 1, 0.7305755019187927, 0.2694244980812073) 1
('1 Kings', 2, 18, 0, 0.36751827597618103, 0.6324816942214966) 1
('1 Kings', 3, 10, 1, 0.7215084433555603, 0.2784915864467621) 0
('1 Kings', 3, 17, 1, 0.7306544184684753, 0.26934558153152466) 1
('1 Kings', 3, 13, 1, 0.7304340600967407, 0.2695659399032593) 1
('1 Kings', 14, 3, 0, 0.2708079516887665, 0.7291920781135559) 1
('1 Kings', 14, 7, 0, 0.46729812026023865, 0.532701849937439) 0
('1 Kings', 14, 20, 0, 0.47423282265663147, 0.5257670879364014) 1
('1 Kings', 9, 2, 1, 0.7310584783554077, 0.2689415216445923) 1
('1 Kings', 9, 7, 0, 0.3240768611431122, 0.6759231686592102) 1
('1 Kings', 9, 23, 1, 0.7310407757759094, 0.2689591944217682) 0
('1 Kings', 1, 47, 0, 0.28992539644241333, 0.7100746631622314) 1
('1 Kings', 1, 15, 0, 0.26894211769104004, 0.7310578227043152) 1
('1 Kings', 1, 21, 0, 0.2689709961414337, 0.7310290336608887) 0
('1 Kings', 1, 33, 0, 0.2767082750797272, 0.72329181432724) 1
('1 Kings', 1, 20, 0, 0.30621787905693054, 0.6937820911407471) 1
('1 Kings', 16, 10, 1, 0.6412263512611389, 0.3587736189365387) 1
('1 Kings', 16, 27, 0, 0.2745169997215271, 0.7254830598831177) 1
('1 Kings', 16, 5, 0, 0.35978707671165466, 0.640212893486023) 0
('1 Kings', 4, 6, 0, 0.4769875705242157, 0.5230124592781067) 1
('1 Kings', 4, 16, 0, 0.4769875705242157, 0.5230124592781067) 1
('1 Kings', 4, 26, 1, 0.7300593256950378, 0.26994070410728455) 1
('1 Kings', 4, 13, 0, 0.4769875705242157, 0.5230124592781067) 1
('1 Kings', 19, 2, 0, 0.2689414322376251, 0.7310585975646973) 0
('1 Kings', 19, 19, 1, 0.7142456769943237, 0.28575432300567627) 1
('1 Kings', 17, 3, 0, 0.2704683840274811, 0.7295315861701965) 1
('1 Kings', 17, 5, 0, 0.26906347274780273, 0.7309365272521973) 1
('1 Kings', 7, 2, 1, 0.7305755019187927, 0.2694244980812073) 2
('1 Kings', 7, 25, 1, 0.7302524447441101, 0.2697475254535675) 1
('1 Kings', 7, 44, 1, 0.7062699198722839, 0.2937300205230713) 1
('1 Kings', 7, 4, 1, 0.7271609306335449, 0.2728390097618103) 1
('1 Kings', 7, 29, 1, 0.6367797255516052, 0.36322030425071716) 1
('1 Kings', 8, 22, 1, 0.7276853322982788, 0.2723146378993988) 2
('1 Kings', 8, 36, 0, 0.2689414322376251, 0.7310585975646973) 1
('1 Kings', 8, 57, 1, 0.73105788230896, 0.26894205808639526) 2
('1 Kings', 8, 50, 0, 0.27761682868003845, 0.7223831415176392) 1
('1 Kings', 8, 27, 1, 0.7310559749603271, 0.26894399523735046) 1
('1 Kings', 8, 12, 1, 0.7306873798370361, 0.26931262016296387) 2
('1 Kings', 15, 22, 1, 0.7310465574264526, 0.268953412771225) 1
('1 Kings', 15, 9, 0, 0.47205525636672974, 0.5279447436332703) 1
('1 Kings', 15, 25, 1, 0.7132042050361633, 0.2867957651615143) 1
('1 Kings', 15, 34, 1, 0.7309011220932007, 0.26909881830215454) 1
('1 Kings', 5, 2, 0, 0.4769875705242157, 0.5230124592781067) 2
('1 Kings', 5, 8, 0, 0.2690545618534088, 0.7309454679489136) 1
('1 Kings', 12, 3, 1, 0.5111242532730103, 0.48887577652931213) 1
('1 Kings', 12, 32, 0, 0.2789941430091858, 0.721005916595459) 1
('1 Kings', 12, 18, 0, 0.2692093551158905, 0.7307906150817871) 1
('1 Kings', 18, 14, 1, 0.690660297870636, 0.309339702129364) 1
('1 Kings', 18, 26, 1, 0.7310585975646973, 0.2689414322376251) 1
('1 Kings', 18, 41, 0, 0.2888687252998352, 0.7111313343048096) 2
('1 Kings', 18, 43, 1, 0.7310584783554077, 0.2689415216445923) 1
('1 Kings', 18, 23, 0, 0.2697809934616089, 0.7302189469337463) 1
('1 Kings', 20, 22, 1, 0.6489856243133545, 0.3510143458843231) 1
('1 Kings', 20, 27, 1, 0.728452742099762, 0.2715473473072052) 2
('1 Kings', 20, 15, 0, 0.28815969824790955, 0.7118402719497681) 1
('1 Kings', 20, 20, 1, 0.6955004930496216, 0.3044995069503784) 2
('1 Kings', 13, 10, 0, 0.29530245065689087, 0.7046976089477539) 1
('1 Kings', 13, 27, 1, 0.5348262190818787, 0.46517378091812134) 2
('1 Kings', 13, 5, 1, 0.7285164594650269, 0.27148348093032837) 1
INFO:tensorflow:Restoring parameters from model/model_finalINFO:tensorflow:Restoring parameters from model/model_final# (Book, Chapter, Verse, Sentiment (0 for neg, 1 for pos), % pos, % neg)
('Colossians', 3, 22, 0, 0.3153419494628906, 0.6846579909324646) 0
('Colossians', 3, 9, 1, 0.7029757499694824, 0.29702427983283997) 0
('Colossians', 3, 12, 0, 0.2689436376094818, 0.7310563921928406) 1
('Colossians', 2, 10, 1, 0.7310583591461182, 0.26894161105155945) 0
('Colossians', 2, 7, 0, 0.2689414322376251, 0.7310585975646973) 0
('Colossians', 1, 6, 0, 0.3082309663295746, 0.6917690634727478) 1
('Colossians', 1, 16, 0, 0.2689417004585266, 0.7310582995414734) 0
('Colossians', 1, 29, 0, 0.4380766451358795, 0.5619233846664429) 0
('Colossians', 4, 11, 1, 0.7296137809753418, 0.2703862190246582) 1
('Colossians', 4, 3, 1, 0.7310153841972351, 0.26898452639579773) 0
INFO:tensorflow:Restoring parameters from model/model_finalINFO:tensorflow:Restoring parameters from model/model_final# (Book, Chapter, Verse, Sentiment (0 for neg, 1 for pos), % pos, % neg)
('2 Corinthians', 5, 5, 1, 0.7244736552238464, 0.2755263149738312) 0
('2 Corinthians', 5, 14, 1, 0.731055736541748, 0.26894429326057434) 1
('2 Corinthians', 7, 7, 0, 0.2700120508670807, 0.7299879193305969) 0
('2 Corinthians', 7, 1, 1, 0.7307299971580505, 0.26927000284194946) 0
('2 Corinthians', 6, 10, 0, 0.2689759135246277, 0.7310240864753723) 1
('2 Corinthians', 6, 13, 1, 0.548064649105072, 0.451935350894928) 0
('2 Corinthians', 11, 2, 0, 0.2700953781604767, 0.7299046516418457) 0
('2 Corinthians', 11, 17, 1, 0.548297107219696, 0.45170286297798157) 1
('2 Corinthians', 11, 12, 0, 0.26894378662109375, 0.731056272983551) 0
('2 Corinthians', 10, 15, 1, 0.7189077138900757, 0.2810922861099243) 1
('2 Corinthians', 10, 9, 0, 0.3321964740753174, 0.6678035259246826) 0
('2 Corinthians', 2, 2, 1, 0.5984526872634888, 0.40154728293418884) 0
('2 Corinthians', 2, 17, 1, 0.6832706332206726, 0.3167293071746826) 1
('2 Corinthians', 4, 14, 1, 0.6880828738212585, 0.31191718578338623) 0
('2 Corinthians', 12, 7, 0, 0.26894256472587585, 0.7310574650764465) 1
('2 Corinthians', 12, 14, 0, 0.2689414322376251, 0.7310585975646973) 0
('2 Corinthians', 9, 7, 0, 0.2689414918422699, 0.7310585379600525) 1
('2 Corinthians', 9, 1, 0, 0.358369916677475, 0.6416301131248474) 0
('2 Corinthians', 1, 10, 1, 0.7310577630996704, 0.2689422070980072) 1
('2 Corinthians', 1, 7, 1, 0.5571672916412354, 0.44283273816108704) 0
('2 Corinthians', 3, 6, 0, 0.26894333958625793, 0.7310566902160645) 1
('2 Corinthians', 3, 16, 1, 0.7310574054718018, 0.26894259452819824) 1
('2 Corinthians', 13, 10, 0, 0.2689415514469147, 0.7310584783554077) 0
('2 Corinthians', 8, 22, 0, 0.2689414322376251, 0.7310585975646973) 1
('2 Corinthians', 8, 9, 0, 0.34308186173439026, 0.6569181084632874) 0
(output truncated ..)How did we do?
Let’s do a quick spot check of our results.
Lookup the most positive verse in 1 Kings:
sqlite> select * from bible where book = '1 Kings' GROUP BY chapter, verse having MAX(pos) order by pos DESC limit 2;
book|chapter|verse|sentiment|pos|neg
1 Kings|3|12|1|0.731058597564697|0.268941432237625
1 Kings|9|1|1|0.731058597564697|0.2689414322376251 Kings 3:12 There’s never been one like you before; and there’ll be no one after.
In my opinion this could go either way but seeing as how this was God himself speaking I guess the model decided that it was a very positive thing.
How about the most positive verses in the whole book?
sqlite> select * from bible GROUP BY chapter, verse having MAX(pos) order by pos DESC limit 10;
book|chapter|verse|sentiment|pos|neg
Lamentations|1|2|1|0.731058597564697|0.268941432237625
Lamentations|1|4|1|0.731058597564697|0.268941432237625
Lamentations|1|5|1|0.731058597564697|0.268941432237625
Ruth|1|6|1|0.731058597564697|0.268941432237625
Daniel|1|7|1|0.731058597564697|0.268941432237625
Hosea|1|8|1|0.731058597564697|0.268941432237625
2 Corinthians|1|9|1|0.731058597564697|0.268941432237625
3 John|1|10|1|0.731058597564697|0.268941432237625
Ephesians|1|11|1|0.731058597564697|0.268941432237625
2 Corinthians|1|12|1|0.731058597564697|0.268941432237625(Interestingly they all have the same value: 0.731058597564697. I suppose this has to do with the internal architecture and weights of the network and how the softmax activation maxed out.)
Lamentations 1:2 She cries herself to sleep each night, tears soaking her pillow. No one’s left among her lovers to sit and hold her hand. Her friends have all dumped her.
This one is a bit of a head scratcher as that verse reads as downright depressing to me. If we think about our training data however, there might be something to the use of these words in the context of movie reviews which skew more positive.
Visualizing summarized results
Let’s write a method to visualize the median sentiment of a book chapter
import pandas as pd
from matplotlib import pyplot as plt
import matplotlib as mpl
import seaborn as sns
%matplotlib inline
def plot_sentiment(book_name):
conn = sqlite3.connect('bible.db')
c = conn.cursor()
c.execute('select * from bible where book="{0}";'.format(book_name))
all_rows = c.fetchall()
conn.close()
def zero_out(row):
if row['pos'] > row['neg']:
row['newpos'] = row['pos']a
row['newneg'] = 0
else:
row['newneg'] = row['neg'] * -1
row['newpos'] = 0
return row
# Load the sentiment data into a pandas dataframe
book = pd.DataFrame(all_rows, columns=['book','chap','verse','sentiment','pos','neg'])
book = book[['chap','pos','neg']].groupby('chap').median().reset_index()
book = book.apply(zero_out, axis=1)
stacked_bar_data = book
#Set general plot properties
sns.set_style("white")
sns.set_context({"figure.figsize": (24, 10)})
#Plot 1 - background - "total" (top) series
sns.barplot(x = stacked_bar_data.chap, y = stacked_bar_data.newneg, color = "red")
#Plot 2 - overlay - "bottom" series
bottom_plot = sns.barplot(x = stacked_bar_data.chap, y = stacked_bar_data.newpos, color = "#0000A3")
bottombar = plt.Rectangle((0,0),1,1,fc="red", edgecolor = 'none')
topbar = plt.Rectangle((0,0),1,1,fc='#0000A3', edgecolor = 'none')
l = plt.legend([bottombar, topbar], ['Negative', 'Positive'], loc=1, ncol = 2, prop={'size':16})
l.draw_frame(False)
#Optional code - Make plot look nicer
sns.despine(left=True)
bottom_plot.set_ylabel("Y-axis label")
bottom_plot.set_xlabel("X-axis label")
#Set fonts to consistent 16pt size
for item in ([bottom_plot.xaxis.label, bottom_plot.yaxis.label] +
bottom_plot.get_xticklabels() + bottom_plot.get_yticklabels()):
item.set_fontsize(14)
2 Corinthians sentiment by chapter
plot_sentiment('2 Corinthians')/Users/jimmie/labs/.venv/std3/lib/python3.5/site-packages/seaborn/categorical.py:1428: FutureWarning: remove_na is deprecated and is a private function. Do not use.
stat_data = remove_na(group_data)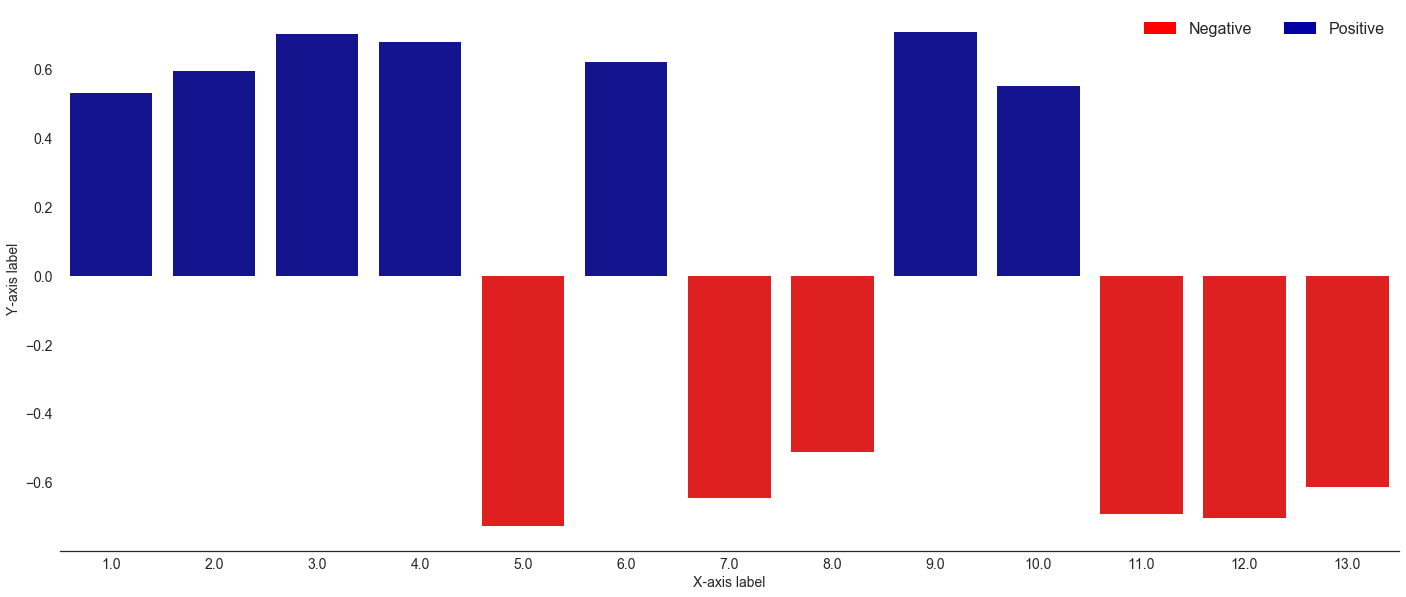
We can probably come up with a heatmap representation to visualize the entire bible as a sentiment grid, an exercise I will leave for the future. In the meantime, I hope you enjoyed this!